オンラインで8月24日~26日にわたって開催の「CEDEC2021」。ここでは、8月24日に行われたセッション「学習ベースの自然な音声合成技術のキャラクターボイスの応用と実運用」の内容をお届けする。
登壇者はスクウェア・エニックスより三宅陽一郎氏と、東芝デジタルソリューションズより倉田宜典氏。このセッションは、ゲームで求められる自然な声を実現する音声合成技術の要件をまとめ、実際にそれらを実装するための手法について説明する。

学習ベースの自然な音声合成技術について
テクノロジー推進部にてAI技術を業務としている三宅氏は、キャラクター会話の中でも自然言語会話を用いた対話によるエンターテイメントAIを目指しており、ゲームのCG技術とAI技術を利用して、ゲームに限らずキャラクター会話を研究していくこと、ゲーム業界だけに囚われずに様々な形で貢献できないかと、研究開発を行っている。
三宅氏によると、ゲーム産業ではシナリオライターが脚本を書いて声優が収録して再生するということを長年やってきており、音声合成は使われてこなかったという。当初予定していた脚本からセリフを拡張したい時もあるため、これまでは開発後期にもう一度音声を収録する期間を設けたり、更に何回もセリフを収録するのも珍しい話ではなく、収録ができない最悪のケースでは拡張のセリフ自体を諦めることもあったが、「収録の状況に依存せずキャラクターの発話を行いたい」「セリフを拡張するためにも音声合成を導入したい」という声が現場から上がってくるようになった。
また、例えばNPCに「あなたはその装備を、あの街で買ったのですね」といったユーザーに依存した情報を話させることで、ユーザーは「このキャラクターが自分のことを理解してくれている」と感じることが出来たり、キャラクターが目の前にいる臨場感を出せるということもあり、よりリアルなゲーム体験が求められている昨今、三宅氏は音声合成技術は基幹技術であると捉えているそうだ。
だが、ゲームが求める音声合成技術のクオリティは他産業よりも高く、個性を持ったキャラクターとしてリアリティを持たなければならない。そのために必要とするクオリティについて、三宅氏は5点を挙げた。
- レベル1「違和感のない声」
ロボティックではない、人間として違和感を覚えない声となる。 - レベル2「ゲームの世界観の馴染む声」
これは舞台が中世や近未来、ファンタジーなど様々な舞台があるゲームの中で、どんな世界観でも使用できる声となる。 - レベル3「他のキャラクターと調和する声」
他のキャラクターの声は生の声優かもしれないし、他のキャラクターも音声合成かもしれないが、いずれも流れを壊す音ではないこと。 - レベル4「その状況に応じたトーンを使い分ける」
戦闘中だったり、緩やかな状況だったり、色んな状況に応じて声のトーンを使い分ける必要がある。 - レベル5「感情を込めた声」
感情は、最も最初に要望が来るものの、最も難易度が高い。激昂、悲しい、緊張感など、いわゆる演技の部分。
これら5つのレベルは、街中のNPCなのか、メインストーリーに絡むキャラクターなのか、ユーザーと共に旅をするレベルのキャラクターなのかによって、求められるレベルが変わる。NPCであればレベル2~3程度でも良く、メインパーティに加わるようなキャラクターであればレベル5が求められる。
ゲームでは、録音の量が開発コストに比例する。できるだけ少ないに越したことはないが、問題は開発側が「もうちょっと話す速度を上げたい」「語尾を上げたい」「方言を喋るのでイントネーションを変えたい」という、凝りたい部分、こだわりの部分、狙った音を作れるという点でも、音声合成ならば開発側で完全にカスタマイズできる。
だが、すぐにゲーム業界にこのレベルの音声合成を取り入れるのは難しく、三宅氏の見通しでは3~4年後を目安に、言語生成AIとあわせてその時々における会話をユーザーと行えるようにしたいという。
その際、レベル1~5にあわせて自然に溶け込んだ会話ができるのはもちろんのこと、「同じ会話ばかり」と言われて30年、これまでのRPGの根底を変え、キャラクターが自ら思考して話したり自律的に話し合うようになるという、よりリッチなゲーム体験が出来るようなビジョンを思い描いているそうだ。
音声合成はまだ導入が検討され始めたばかりの技術であり、完全にゲーム内で使用できるには至っていないからこそ、機械学習の工程やアルゴリズムを透明化し、技術的な原因を知った上で対策するためのノウハウを貯めたいということ、一度行った音声合成の辞書が再利用できてAというタイトルで使用した音声合成がBというタイトルでも再利用できるように積み重ねられるようにしたいという。
音声合成を活用した実際のサービス
ここからは、倉田氏がマイクを取る。倉田氏は、20年ほど合成音声を利用するユーザーとして、合成音声に深く関わっていた。バーチャルアナウンサーや擬人化アプリ、「ソードアートオンライン」のアスナのアプリを合成音声で喋らせるなど、様々なアプリケーション開発のプロデュースを行い、機器類の中にも対話機能を使用していたが、現在は自ら合成音声の開発を行っており、先日新標品を発売したばかりだという。
音声合成は日々進化している技術だが、進化の過程においても構造があまり変わっておらず、主にシンセサイザーモジュールなどが変わっているそうだ。音素が分割したのをつなげていたのが、波形接続方式。そこからHMM(隠れマルコフモデル)で学習させる方式が現れ、2013年にはDNN(ディープニューラルネットワーク)方式による合成音声が開発され始めた。この機械学習結果で、音声が変わってくる。
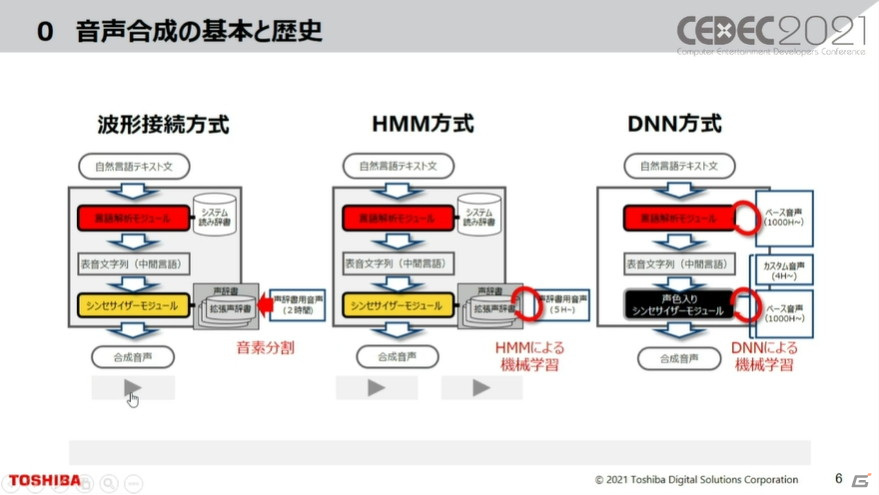
なお、HMMの合成音声からDNNに移行はしているものの、HMMでもまだ研究開発は行われている。HMM型でもDNNでも声質はほぼ人間と同等で、現在はそこから更なる進化が求められている段階だという。
では実際に合成音声を作成していく手順を紹介しよう。
1. 声の素を作る
どういう合成音声を作成するかを決めるため、声のモデル声の素を作成する。大体の合成音声のゴールがここで決まってしまうというほど非常に重要な要素で、どういうデータをどういう方向で収録するか、どういう声主から音源を確保するかが、最終的な学習に影響する。
一番重要なのは方向性で、オーダーをしているユーザー側がイメージしている音声と、作りて側がイメージする音声が異なっていると、出来上がった時に「これは違う」ということになってしまう。
各社で収録方法は異なるが、基本的にはスタジオなど雑音が混ざらない空間で、出来るだけ綺麗な音を確保できるようにすることが重要で、声優やアナウンサーなど綺麗な発音が出来る人のほうが、良い音声になる。機械学習の工程は各社様々だが、出来上がってきた声を更に各社のエンジニアが調整していくことで完成する。
声のテンションも非常に重要で、特に声優の場合はひとりで七色の声音を使い分けることも可能なため、ひとつの声の素に様々なテンションの声を混ぜてしまうと機械学習がうまくいかなくなるという。同じ声優を使用して別のパターンの音声を作成する場合、声の素自体を更に別に収録することで、機械学習で違う声音の声が作れるそうだ。
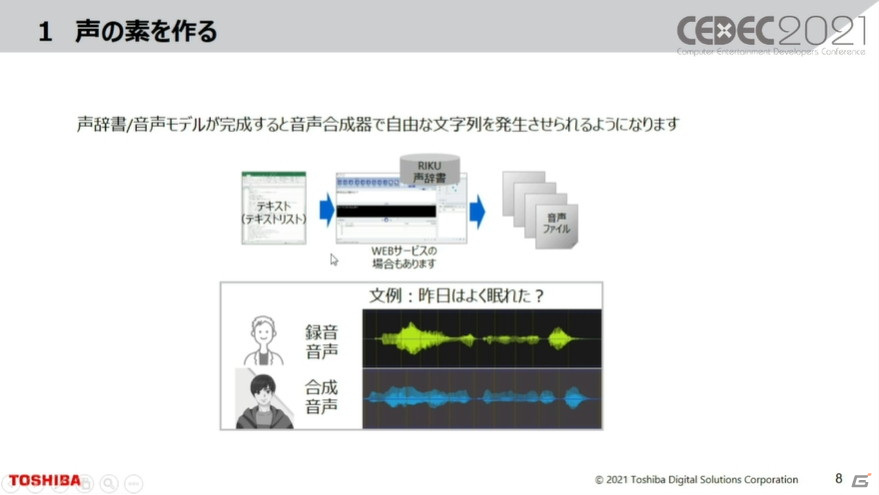 |
| 録音した生の音声と合成音声のサンプルが流れたが、キーは少し違うもののほぼ同じだった。 |
2. 好みの表現
オリジナルの台本では大抵アクセントは指定されていないので、「方言にしたいからアクセントを変えてほしい」「間をおきたい」「強く喋りたい」といった細かい要望に応えていく。
音声合成共通のマークアップ言語としてSSMLタグを使用し、アクセントをつけたい場所などにその都度コマンドを入れることが出来るものの、これをやり込んでいくと段々文字列そのものが読めなくなるので、SSMLタグでやるのは最終手段。可読性を上げるために、表音文字列という簡単な文字列に置き換え、記号で調整するケースが多い。

人間が喋ったことを真似させることも出来る韻律射影(韻律転移)と呼ばれる技術を使い、それをキャプチャーして分析して合成音声で表現するという技術がある。
例えば「昨日はよく眠れた?」という言葉に対して、通常は無難な音程変化で合成音声を生成するが、違う読みをさせたい場合にはイメージした調子で演じた音声を合成音声に真似させると、テンポや抑揚がほぼ一致するように作れるのだ。作業時間も短いため、韻律射影は注目されている技術だという。

3. 生音声と合成音の差異の軽減
合成音声は激しい演技や細かい演技をジェネレートすることが苦手で、現状では生声を喋らせてから必要な情報を合成が喋り、また生声に戻す、というような生声と組み合わせて使うケースが多い。だが、その際には生の音声と合成音声との音質の差異が気になるという課題が起こるため、少しでもその差異を軽減するポイントとして、再生される音声のサンプリングレートは合わせることが重要であることや、使っているシーンによって音声合成の読み上げ速度を生声に合わせることを挙げ、つなぎ目のところで無音部分が長かったり間がなくなると不自然になることを挙げた。
会場では実際に生声で録音した「これで明日の試験はなんとかなるかな~」というデータに「英語の」という合成音声を足して、「これで明日の(生声)“英語の(合成音声)”試験はなんとかなるかな~(生声)」というデータのサンプルが流れたが、若干気になる部分はあるものの、聞き流している分にはいけるのではないか、と感じるクオリティのものとなっているように感じた。倉田氏も「まだこのレベルではありますが、なんとか流れのあるセリフならば良いかな、というところまでは行けたのでは」と語った。

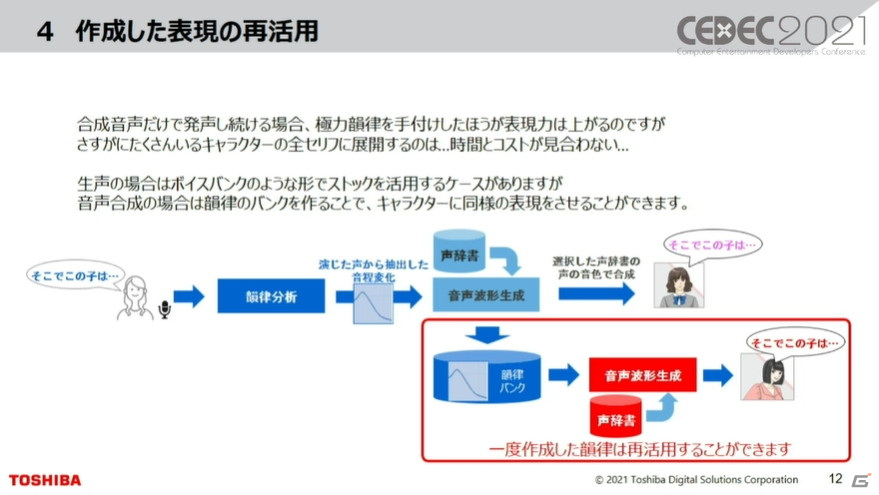
4. 作成した表現の再活用
合成音声だけで発生し続ける場合、極力韻律を手動で付けた方が表現力は上がるものの、全てのキャラクターの全てのセリフに手動で付けるには、手間と時間がかかる。つまり、コストもかかる。そのため倉田氏がお勧めしているのは、韻律バンクの作成だという。
生声でもボイスバンクのようにストックをするケースがあるが、音声合成では韻律のバンクを作ることで、キャラクターに同様の表現をさせることが可能になる。
また、Aというキャラクターのために作っておいた韻律バンクでも、全然異なる作品のBというキャラクターにその韻律バンクを使うこともできるため、一度作成した韻律は再活用することが出来るようになる。
音声合成をキャラクターの発声に使えるようになれば、新しい顧客体験を提供できると言われているが、クオリティー面での問題でなかなか採用が進んでこなかった。しかし、AI技術の進化で各社から質が高い音声合成製品やサービスが提供され始めてきており、改めてゲーム/アプリに音声合成を活用する際、気になりそうなポイントとして具体例を挙げたという、倉田氏。
これを手作業でやっている現在はまだ前半戦の段階で、いずれはAIで自動で音声合成が能動的に表現を変えるところまで辿り着くのがAIの目指すひとつのゴールだという。どんどんノウハウを貯めて使いこなし、ゲームユーザーが驚くような体験を創造してみてほしい、と熱く語りかけた。
倉田氏と三宅氏、それぞれの立場からの音声合成
ここからはパネルディスカッションの形で、三宅氏と倉田氏がお互いに意見を交わし合っていたので、その模様をお届けしよう。
三宅氏:倉田さんは音声合成を使う側と提供する側というふたつの立場を経験していますが、だからこそ見えてきたことはありますか?
倉田氏:見えてきたことというか、変わったこととして2点あります。
ひとつは、二足ロボットのデモを作っていた頃の音声合成は質が悪くて、でも抑揚をつけると周りの人が途端に聞いてくれるようになったんです。人の耳に届く抑揚や韻律はとても大事で、その出来不出来で訴える力が全然変わるのですが、それが実現できなかったんですね。でも自分が作る側になることで、それができるようになりました。
もうひとつは、以前は自分はユーザー側だったので他のユーザーのニーズを知らなかったですし、どういうものが求められているのかを知らずにいたけれど、作る側だとこういう用途や考え方もあるのかということを知れて、世界の幅が広がりました。
三宅氏:提供する側だと、ユーザーのちょっと無理難題のような要望でも、「これは出来ちゃうかも」というのもありますか?
倉田氏:ありますね。テーマによってはもちろん重いものもあったりしますが、「それならば、こういうことができる」という違ったアプローチからの提供も出来ますので。
三宅氏:作った中で、思い出深いものはありますか?
倉田氏:ソニーに勤めていた頃に東芝と作った声辞書の高品質版は、収録をどれくらいやればいいのか解らずに、とてつもない量の録音をしました。声優さんもへろへろになっちゃって、とても申し訳なかったなぁ、と(笑)。
三宅氏:音声合成は、ゲーム産業とそれ以外でどれぐらい導入されているものなのでしょうか?
倉田氏:音声合成は必須な場所のみで使われているもので、エンターテイメントではまだまだ至らない、使わない、という時代が長かったです。これまで作ったタイトルは、音声合成を活かしてトライアルをしたいという、実験的なケースが多いです。ですが、ここ数年の進化で工夫次第で本格的に使えるんじゃないか、というゾーンに入り始めたのではないかと思っています。合成音声を使うことでコストを抑えたりも出来るようになってきましたので、興味がある方はぜひご連絡ください。
 |
| 倉田氏の問い合わせ先 |
倉田氏:僕から三宅さんにお尋ねしたいこともあるのですが、ゲーム産業で音声合成に求めるものや期待しているものはありますか? また、納期はどれくらいの期間が欲しいですか?
三宅氏:携帯ゲームならば1~2年ほどの開発期間という短期開発で、大型ゲームの場合は数年と立場は違いますが、「音声合成でいける」とい確信できる温度感は、開発から半年後くらいまでには欲しいですね。やはりこちらとしても、上手くいくのかやクオリティコントロールが出来るかというのは不安点です。携帯ゲーム、プロモーション用途、WEBなどから大型ゲームによって求めるものは全然変わってきますが、メインに使えるのかNPCくらいにならば使えるのか、こちらも初めてのことなので、技術的な工数の見積もりが欲しいです。
倉田氏:メインキャラクターに使うとなるとだいぶ要求が変わりますし、コストも変わりますね。その中でも生声と連携をさせるのか、全て音声合成なのかでもゴールが変わりますし……。音声合成がまだ出来ない領域を踏み越えた要望がくれば、そこは早めに「出来ないです」とお伝えしたいと思います。ゲームのサウンドクリエイターさんは、自分たちで何とかしようとされるので、こちらから道具を提供するのはとても重要だと思います。皆さん、こちらが思っている以上に使いこなせるので、それによってクオリティにも大きな差が出てくると思います。
三宅氏:違和感のない音声合成は可能ですか?
倉田氏:使う用途にもよりますが、例えばプレイヤーガイドのような音声ならば、今の音声合成でも違和感ないかと思います。ですが、声優さんがやっていたことをそのまま音声合成にしようとすると、丁寧にアプローチしなければならないですね。周囲に対してどういう喋りをしているのかを無視してプレーンな合成音声を流すと、空気の読めない声になってしまうんです。例えば先程の音声データのように「英語の試験」的な単語であれば、違和感なく入っていける部分はあると思います。
三宅氏:ゲーム産業からの要望でおどろいた案件はありますか?
倉田氏:ゲームによって、どう使いたいのか全く違うところです。本当にメインに使いたい場合はハードルが高い一方で、インディーズゲームでちょっと使いたい、というような案件もあるんですよ。「とにかく伝わりさえすれば良い」くらいで安く早く、というものもあれば、時間もお金もかかっていいから品質を最重要視してほしいというものまで、ゲーム業界は本当に要望が幅広いですね。なので、プロデューサーやディレクターとしっかり話をして、何を求めているのか、こちらからどのようなことが出来るのかを丁寧にお伝えすることが大事だと思います。

以上で本セッションは終了となったが、倉田氏も語っていたように、わざわざ声優を起用しなくともちょっとした音声であれば音声合成を使用するという道もあるだろう。更には、倉田氏が開発に携わった「Voice Track Maker」という、文字情報から様々な音声表現を作成することができるPCツールもある(https://voicetrackmaker.bp.recaius.jp/)。
より上質なゲーム体験から、安価に作成したいというニーズにまで幅広く応えられるだけに、今後の発展に注目したい。
本コンテンツは、掲載するECサイトやメーカー等から収益を得ている場合があります。
































